
PhD Thesis

Hai-Vy Nguyen, PhD Thesis, 2025, Université de Toulouse.
This PhD thesis investigates how the geometry and structure of feature representations shape the behavior and reliability of deep neural networks. It is organized around four complementary directions: robust training, feature representation transfer, uncertainty quantification, and spatially structured attention.
- Robust Training: A simple framework combining penultimate-layer objectives and Gaussian noise injection improves robustness while preserving clean accuracy, supported by a theoretical link to reduced curvature of the loss landscape.
- Representation Transfer: A perception coherence principle enables efficient knowledge transfer by aligning relational structures in feature space between teacher and student models.
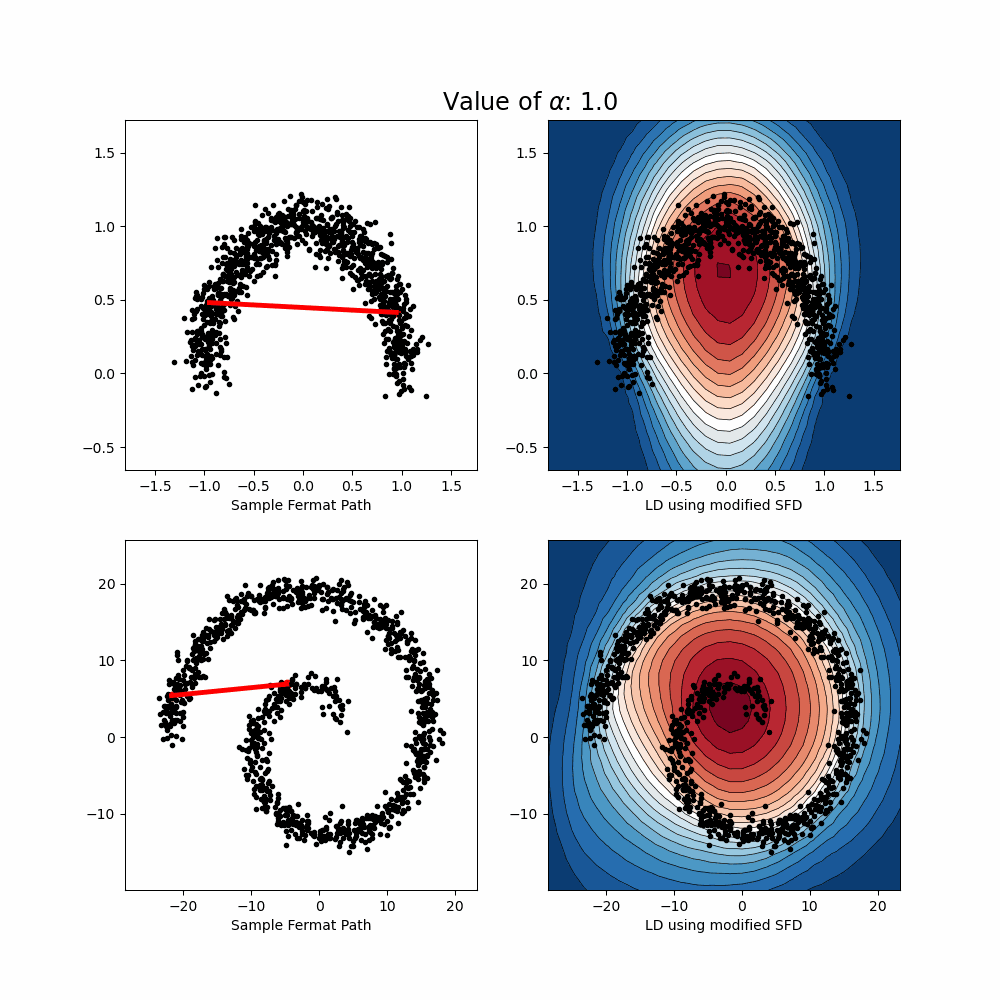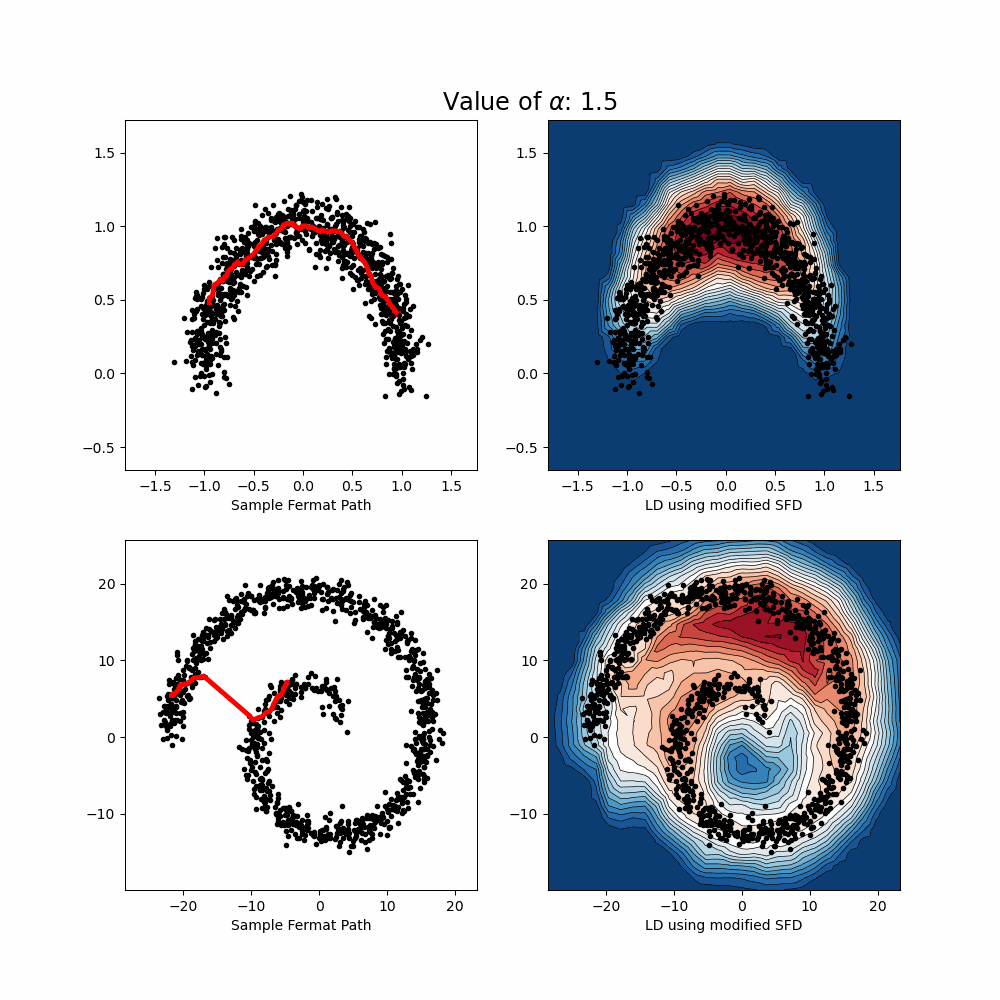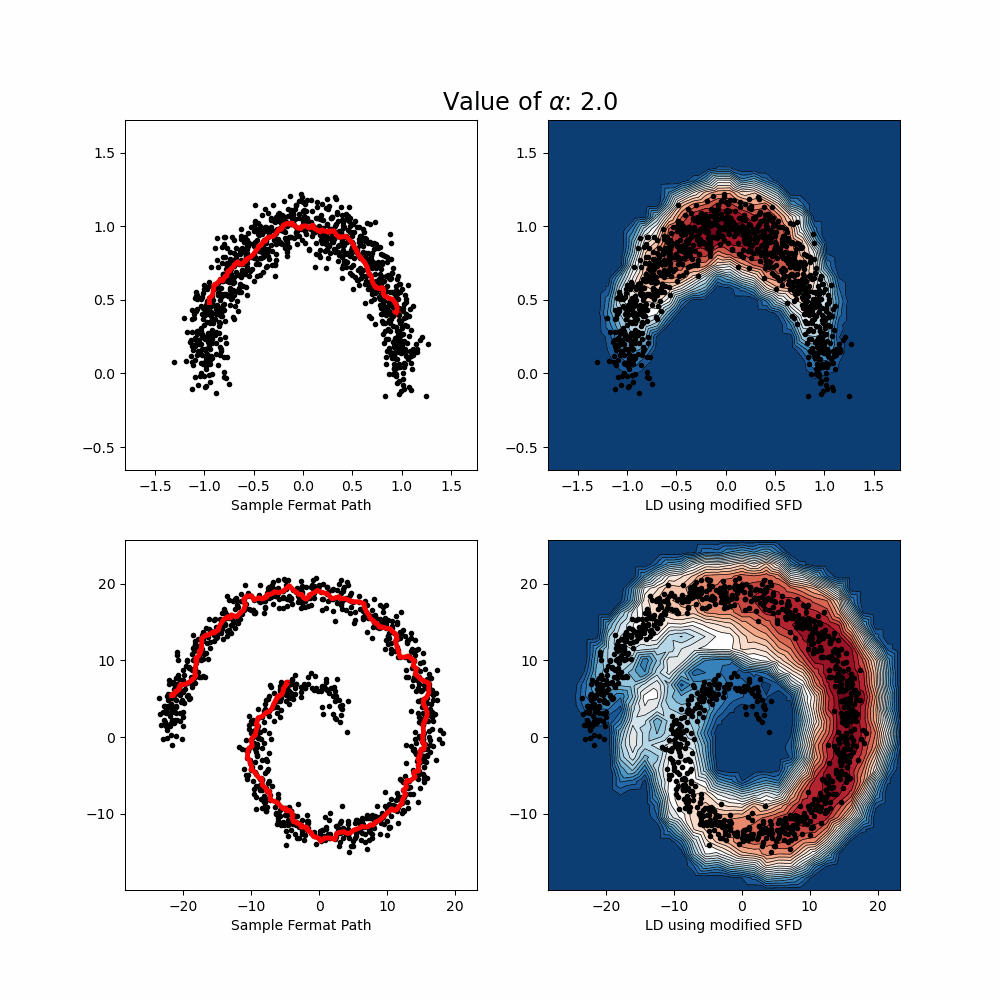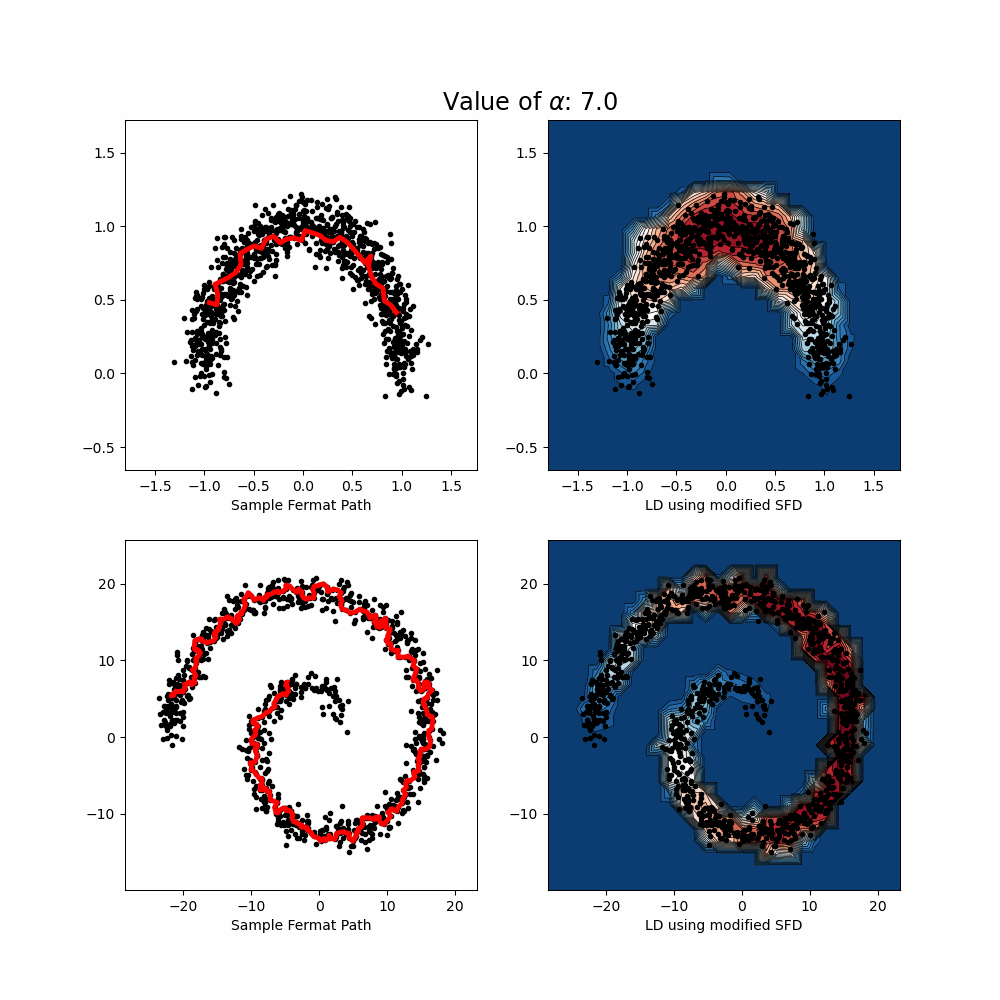
- Uncertainty Quantification: A post-hoc method based on Lens Depth and Fermat distance leverages feature-space geometry to detect out-of-distribution inputs in a scalable and model-agnostic way.
- Structured Attention: A rectangular attention module provides low-dimensional, interpretable spatial focus, improving stability and performance under geometric transformations.
Overall, this work highlights that feature-space geometry is a central principle for understanding, improving, and transferring deep learning models.
Publications
Hai‑Vy Nguyen, Fabrice Gamboa, Reda Chhaibi, Sixin Zhang, Serge Gratton, Thierry Giaccone
NeurIPS 2024 (Main Conference)
This paper introduces a new framework for uncertainty quantification based on geometric principles in the feature space of neural networks. The method relies on two complementary ideas:
- Lens Depth: a statistical depth function that measures how “central” a test point is with respect to the training data distribution. It reflects how likely a point is to belong to a data manifold, based on its spatial relation to pairs of training points.
- Fermat Distance: a distance that favors high-density regions. It constructs a path that adapts to the data distribution and geometry.
By combining these two quantities, we define an uncertainty score that quantifes the degree of "out-of-distribution'' (or centrality) with respect to a given distribution, taking into account its geometry and density. The score requires only the feature embeddings from a pre-trained model — no changes to training or retraining are needed. The proposed approach is non-parametric and model-agnostic. This work demonstrates that geometric insights in feature space can lead to powerful uncertainty quantification tools, suitable for real-world deployment.
Hai‑Vy Nguyen, Fabrice Gamboa, Sixin Zhang, Reda Chhaibi, Serge Gratton, Thierry Giaccone
Transactions on Machine Learning Research - TMLR (12/2025)
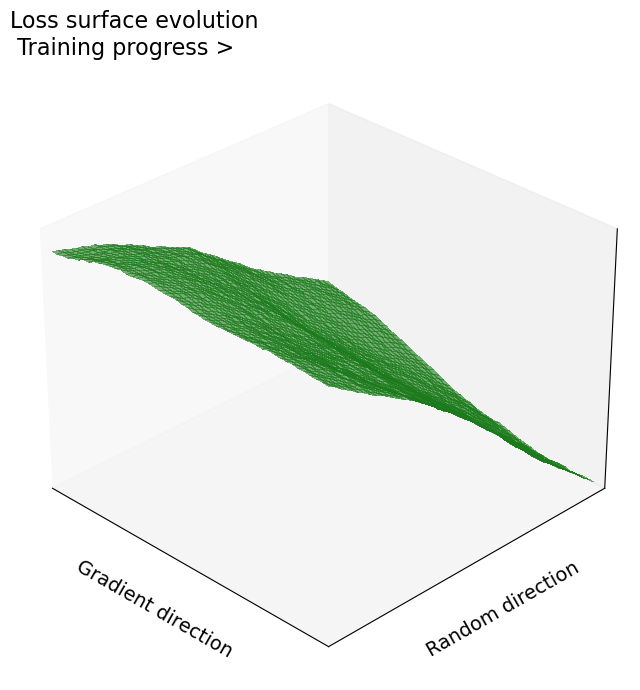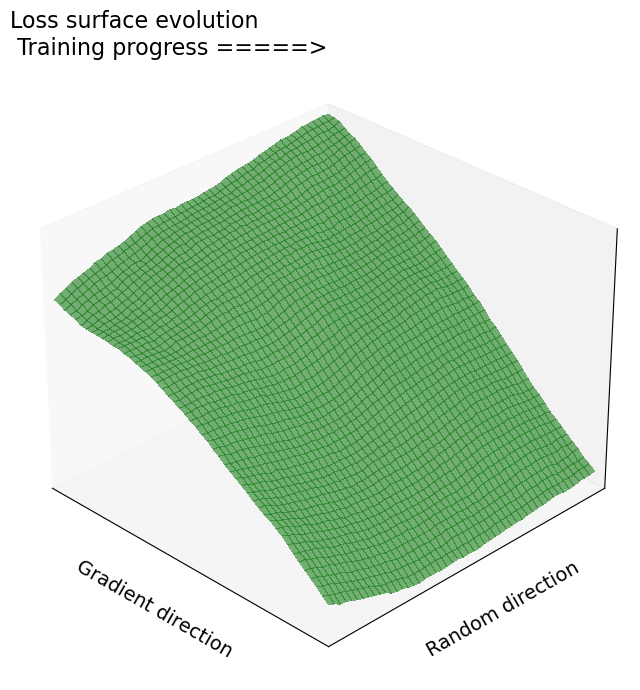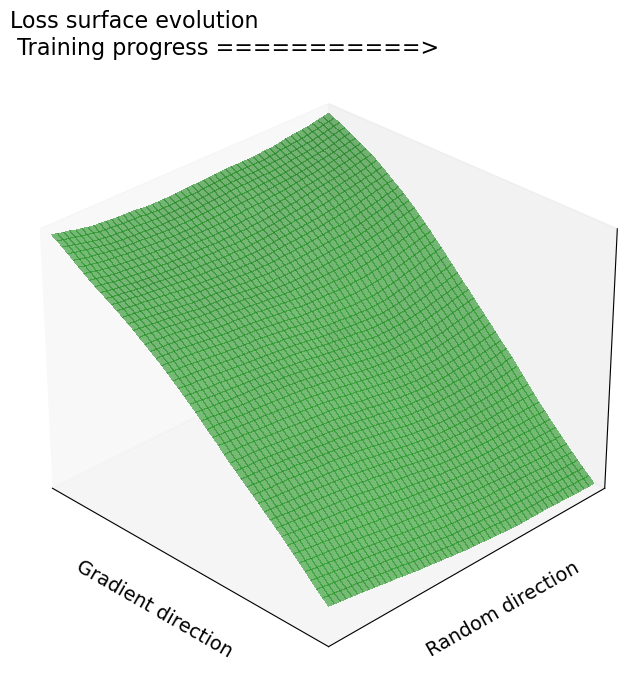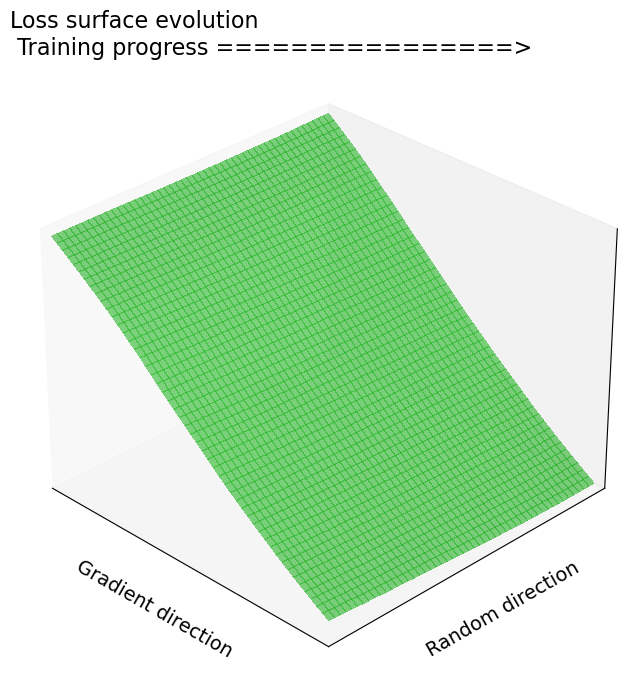
We propose a novel training framework for noise-robust deep neural networks that addresses the trade-off between robustness and clean-data accuracy. Our approach combines a penultimate-layer loss that enforces intra-class compactness and margin maximization with a class-wise feature alignment mechanism that aligns noisy and clean feature clusters. Furthermore, we provide a theoretical analysis showing that stabilizing features under Gaussian noise reduces the curvature of the loss landscape, enhancing robustness without explicit curvature regularization.
- Penultimate-Layer Objective: Improves feature discriminativeness and class separability by enforcing compactness and margins to analytical decision boundaries.
- Class-Wise Feature Alignment: Brings noisy feature clusters closer to their clean counterparts, enhancing stability under input perturbations.
- Theoretical Guarantee: Demonstrates that reduced curvature (Hessian eigenvalues) in input space correlates with improved robustness.
- Robust Performance: Validated on standard benchmarks and a custom dataset, achieving robustness gains without sacrificing accuracy on clean data.
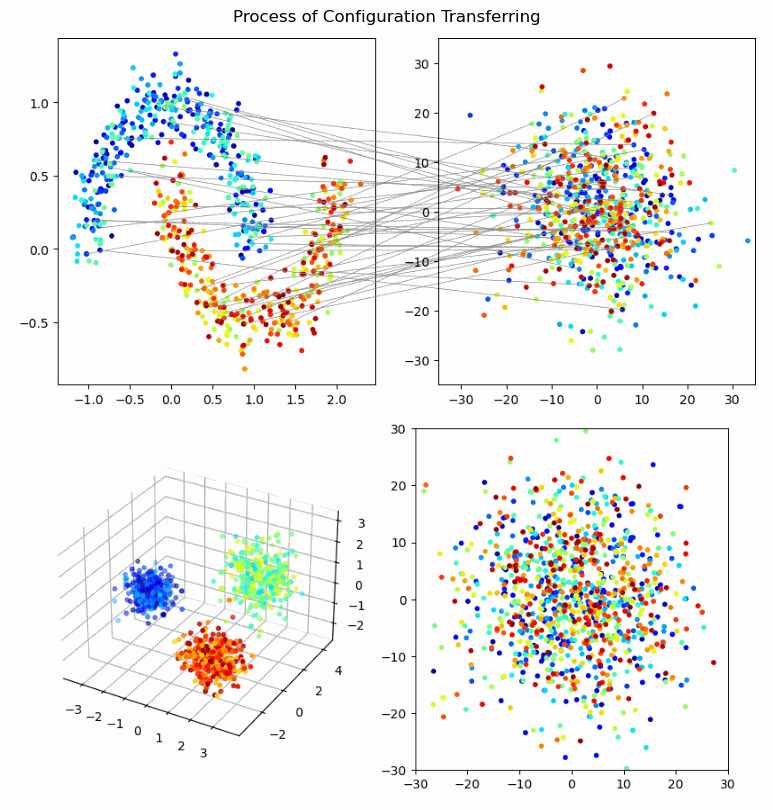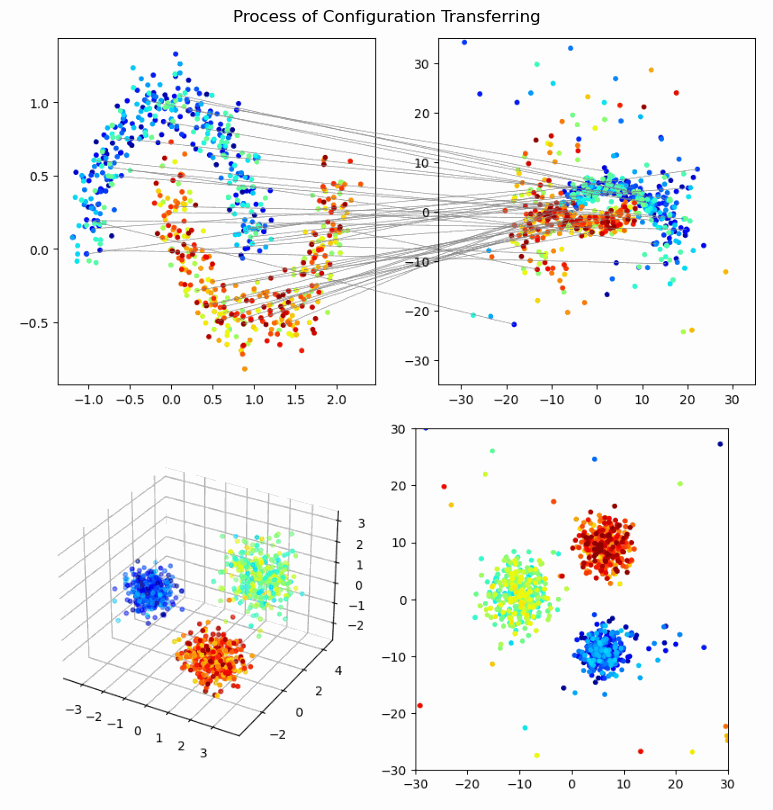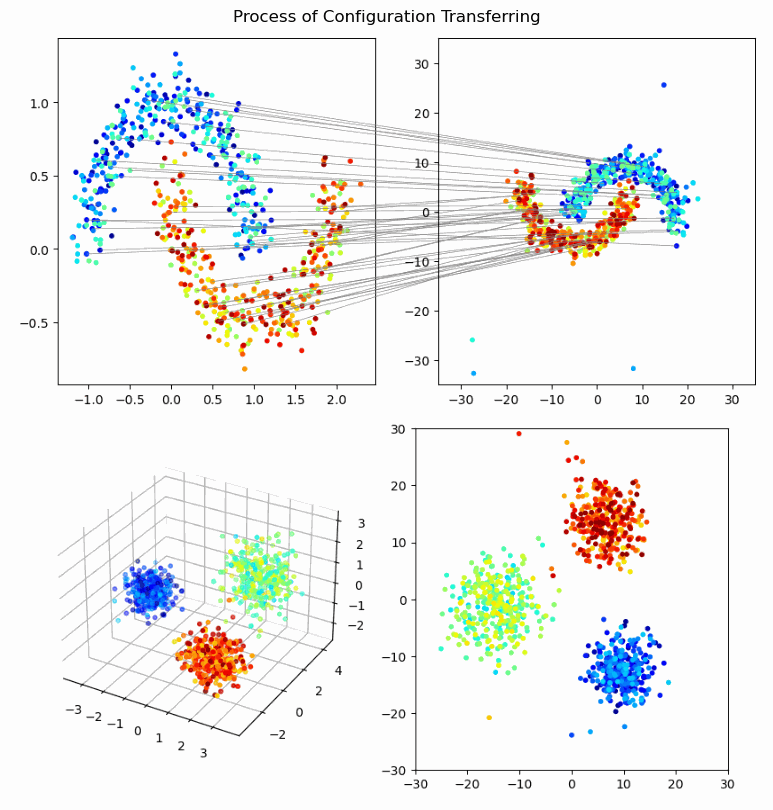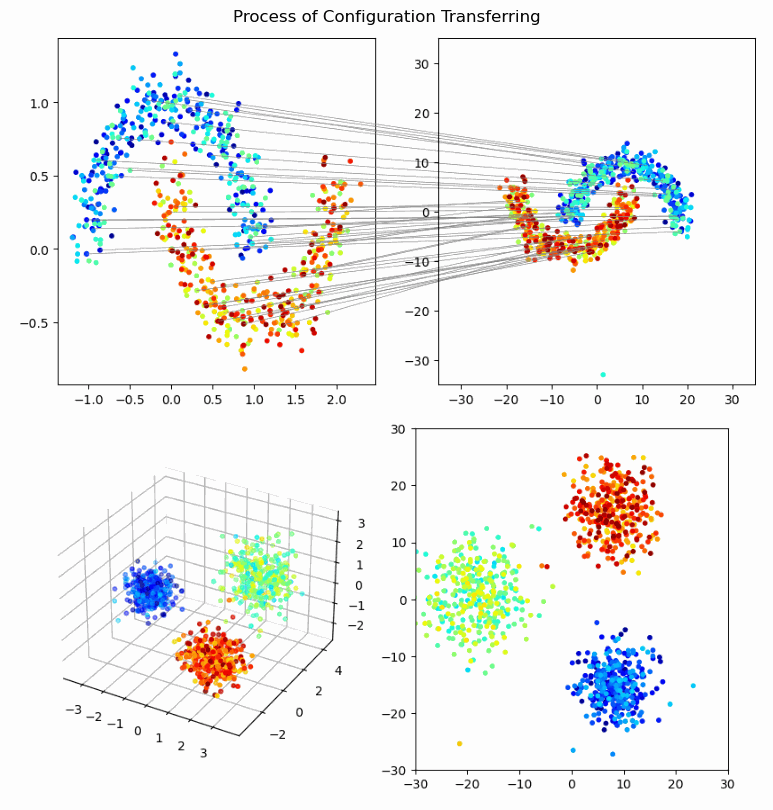
Hai‑Vy Nguyen, Fabrice Gamboa, Sixin Zhang, Reda Chhaibi, Serge Gratton, Thierry Giaccone
Transactions on Machine Learning Research - TMLR (02/2026)
We propose a novel framework for knowledge transfer from large teacher models to lightweight student models. Our approach introduces perception coherence, a probabilistic notion that ensures the student model mimics the teacher’s perception of relative similarities between inputs, without needing to exactly replicate feature geometries or distributions. This is particularly useful when student models have lower capacity or different feature dimensions than the teacher.
- Perception Coherence Loss: A ranking-based differentiable loss that encourages the student model to maintain the teacher's dissimilarity ordering among inputs.
- Flexible Representation Transfer: The method focuses on global coherence rather than exact feature matching, allowing more effective knowledge distillation for smaller models.

Hai‑Vy Nguyen, Fabrice Gamboa, Sixin Zhang, Reda Chhaibi, Serge Gratton, Thierry Giaccone
Preprint, 2024
We introduce a novel spatial attention module for convolutional neural networks that guides the model to focus on the most discriminative regions of an input. Unlike conventional position-wise attention maps, which often produce irregular boundaries and hamper generalization, our method constrains the attention region to a rectangular support, parametrized by only five parameters. This design improves stability, generalization, and interpretability, enabling the model to learn where to look while training end-to-end.
- Rectangular Attention: Smooth rectangular attention supports that respect equivariance to translation, rotation, and scaling.
- Theoretical Insights: Analysis of how predicted attention maps align with ground-truth and improve feature separability in classification tasks.
This module provides a simple yet effective attention mechanism that can be integrated into any CNN for improved performance and interpretability.